Description
Here we provide a description and explanation of constructions that we use in GalaxyWitness
About witness complex
The witness complex \(\mathrm{Wit}(L,W)\) (a “discrete” analogue of the Delaunay complex) this is a simplicial complex defined by two sets in \(\mathbb{R}^d\):
\(L\) - the set of landmarkets
\(W\) - the set of witnesses
We will also assume that \(L\subseteq W\). The vertices of \(\mathrm{Wit}(L,W)\) are the set \(L\). The complex \(\mathrm{Wit}(L,W)\) (strong version) is a flag simplicial complex consisting of all simplices \(\tau\) such that the following condition holds for any simplex \(\sigma\subseteq\tau\):
Now we similarly introduce (\(\alpha\)-relaxed) complex \(\mathrm{Wit}^{\alpha}(L,W)\), defined by the condition:
Varying the parameter \(\alpha\), we get the filtering of witness complex:
About simplex tree
Let \(K\) be a simplicial complex with \(n\) vertices. Recall that by filtering we mean the function \(f:K\to\mathbb{R}\), such that \(f(\sigma)\leq f(\tau)\) only if \(\sigma\subseteq\tau\).
A simplex tree is Trie (prefix tree), in which the keys are words (simplices) in the alphabet \(1,...,n\), and the values are the filtering values \(f\)

Simplicial complex and its simplex tree: all values equals 1
You can read more about the simplex tree in the article:
About clustering (ToMATo)
ToMATo is a clustering algorithm. ToMATo starts with a graph \(G\), for example, graph k nearest neighbors , then using the density function defined on the point cloud, combines the pieces of the original graph and obtains the required clustering (which is determined by the number of clusters and/or the threshold of significance per density function). This algorithm is a composition of two ideas: Union-find forest and Morse theory. Let \(f\) be a density function. Let’s describe the steps of the algorithm:
We construct a graph \(G\) (\(k\) nearest neighbors or a Rips graph with the parameter \(\delta\)).
Passing through the vertices of the graph: connect the current vertex \(v\) with the neighboring \(w\) if \(f(w)\) is the largest value of \(f\) among the vertices adjacent to the vertex \(v\). We get a spanning forest on the vertices of the original graph \(G\). Moreover, the root of each tree will be a vertex with a local maximum of the density function.
We combine trees whose roots have a small value of the density function. Namely, we connect the roots of two trees from the root with a smaller value of the density function to the function with a larger value of the density function. We continue until the required clustering is obtained.
You can read more about ToMATo in the article:
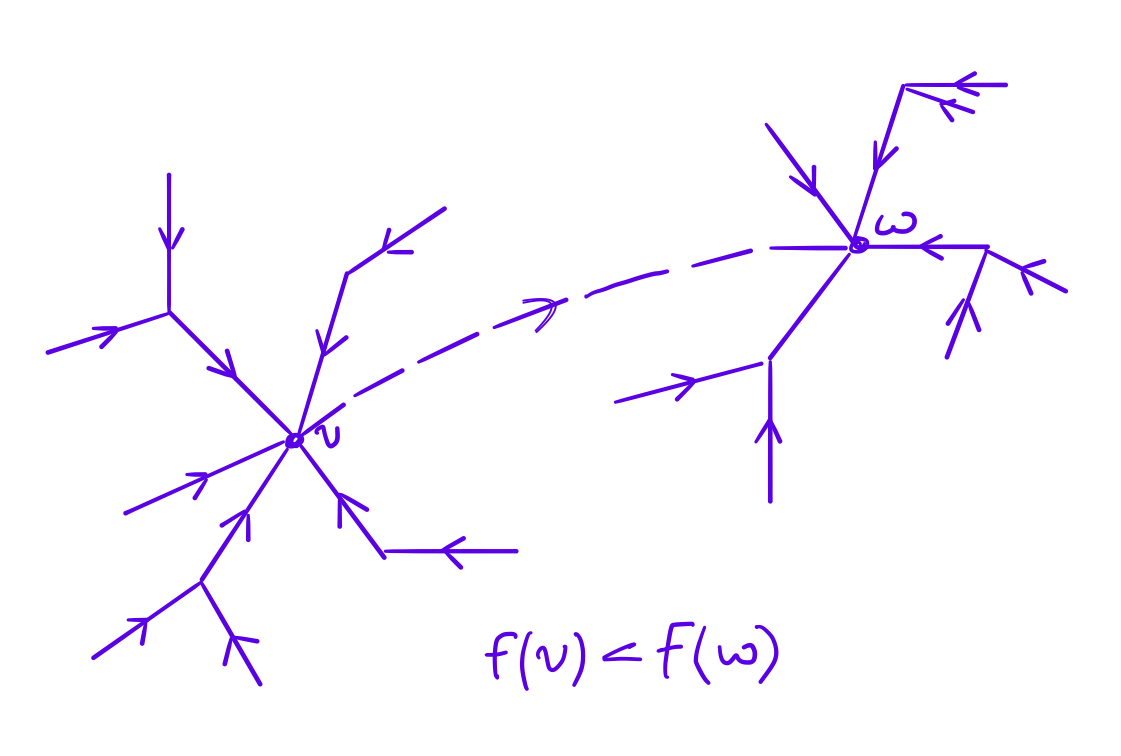
Merge of two trees
About Delaunay triangulation
Coming soon…